2022/04/17 更新
我目前使用的方案是 rsshub,自己部署 freshrss,使用 reeder 订阅。稳定性和易用性都比下面的方案好了,更推荐。
工作的时候没法做到时刻经常刷雪球,但是又不想错过某个用户的发言怎么办呢?解决办法就是 huginn + 钉钉群。
huginn 负责信息抓取、处理和调用钉钉群组机器人的 API,每 10 分钟在服务器上跑一次(过短可能触发雪球的防爬虫机制,我没有测试更短的间隔)。钉钉用来看消息。实现的效果如下图: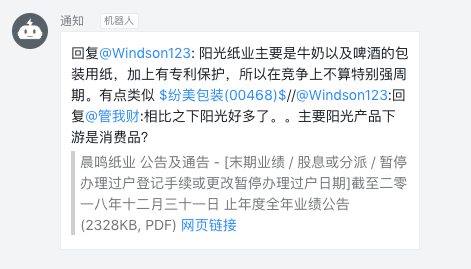
部署 huginn
部署 huginn 需要一台 vps,推荐购买 linode 的机器。注意不能选择那些内存过小(如 128M)的 vps,huginn 对机器的要求稍微有些高
使用 docker 的部署方式可以选择用 iOS 上的 hyperapp 一键完成
雪球 scenario
整体结构图如下: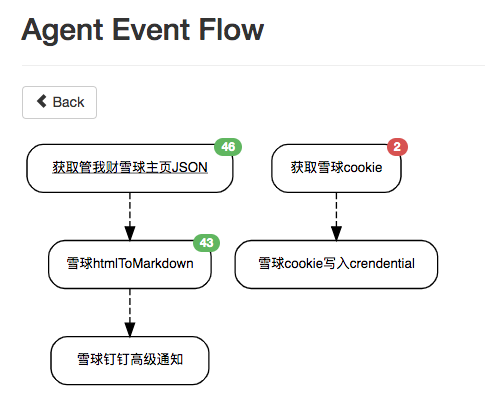
此处以抓取财主的发言做为例子
0. 维护雪球 cookie
新建一个 post agent,每 2 小时运行一次:
{
"post_url": "https://xueqiu.com",
"expected_receive_period_in_days": "1",
"content_type": "form",
"method": "get",
"payload": {
},
"headers": {
},
"emit_events": "true",
"no_merge": "false",
"output_mode": "clean",
"disable_redirect_follow": "true"
}
这一步核心目的是模拟登录一次雪球,获取到雪球自己主页的 js 回写的 cookie
然后去新建一个 credential,名叫 xueqiu_cookie。接一个 javascript agent
Agent.receive = function() {
var events = this.incomingEvents();
for(var i = 0; i < events.length; i++) {
const cookies = events[i].payload.headers['Set-Cookie']
if (cookies) {
this.log(cookies)
this.credential('xueqiu_cookie', cookies);
}
}
}
这段 js 会把上一个 agent 获取到的 cookie 写到我们自己的 xueqiu_cookie 变量上
1. 获取财主雪球主页列表
接口可以通过 chrome 调试雪球的 PC 网站看到,就是一个普通的 get 请求。注意需要带上特定的 cookie
新建一个 Website Agent,配置内容:
{
"expected_update_period_in_days": "2",
"url": "https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=9650668145",
"type": "json",
"mode": "on_change",
"extract": {
"title": {
"path": "statuses[*].description"
},
"retweeted": {
"path": "statuses[*].retweeted_status"
}
},
"template": {
"retweeted": "{% if retweeted %}{{ retweeted.description }}{% else %}{% endif %}"
},
"headers": {
"Cookie": "{% credential xueqiu_cookie %}"
}
}
数据解析用的是 jsonpath,template 字段可以对 jsonpath 得到的 value 做进一步的处理,而且可以写简单的逻辑。比如我这里的处理是过滤了 retweeted 为 null 的情况
2. 将获取到的 html 转为 markdown
钉钉的群机器人接口支持 markdown 的渲染,所以这一步需要将雪球接口里获取到的 html 内容转为 markdown
至于如何用 js 实现这个转换,可以去 github 上搜索,相应的库并不少。但是因为 huginn 无法使用 npm 和引入外部的 js,所以我这里找了一个非常简单的实现去做转换
新建一个 huginn 的 javascript agent,js 的部分如下。这里我改了原脚本对 img 的处理,直接去掉了所有图片,原因是钉钉不支持 markdown 对图片大小的调整
var toMarkdown = function(string) {
var ELEMENTS = [
{
patterns: 'p',
replacement: function(str, attrs, innerHTML) {
return innerHTML ? '\n\n' + innerHTML + '\n' : '';
}
},
{
patterns: 'br',
type: 'void',
replacement: '\n'
},
{
patterns: 'h([1-6])',
replacement: function(str, hLevel, attrs, innerHTML) {
var hPrefix = '';
for(var i = 0; i < hLevel; i++) {
hPrefix += '#';
}
return '\n\n' + hPrefix + ' ' + innerHTML + '\n';
}
},
{
patterns: 'hr',
type: 'void',
replacement: '\n\n* * *\n'
},
{
patterns: 'a',
replacement: function(str, attrs, innerHTML) {
var href = attrs.match(attrRegExp('href')),
title = attrs.match(attrRegExp('title'));
return href ? '[' + innerHTML + ']' + '(' + href[1] + (title && title[1] ? ' "' + title[1] + '"' : '') + ')' : str;
}
},
{
patterns: ['b', 'strong'],
replacement: function(str, attrs, innerHTML) {
return innerHTML ? '**' + innerHTML + '**' : '';
}
},
{
patterns: ['i', 'em'],
replacement: function(str, attrs, innerHTML) {
return innerHTML ? '_' + innerHTML + '_' : '';
}
},
{
patterns: 'code',
replacement: function(str, attrs, innerHTML) {
return innerHTML ? '`' + innerHTML + '`' : '';
}
},
{
patterns: 'img',
type: 'void',
replacement: function(str, attrs, innerHTML) {
var src = attrs.match(attrRegExp('src')),
alt = attrs.match(attrRegExp('alt')),
title = attrs.match(attrRegExp('title'));
// return '![' + (alt && alt[1] ? alt[1] : '') + ']' + '(' + src[1] + (title && title[1] ? ' "' + title[1] + '"' : '') + ')';
return ''
}
}
];
for(var i = 0, len = ELEMENTS.length; i < len; i++) {
if(typeof ELEMENTS[i].patterns === 'string') {
string = replaceEls(string, { tag: ELEMENTS[i].patterns, replacement: ELEMENTS[i].replacement, type: ELEMENTS[i].type });
}
else {
for(var j = 0, pLen = ELEMENTS[i].patterns.length; j < pLen; j++) {
string = replaceEls(string, { tag: ELEMENTS[i].patterns[j], replacement: ELEMENTS[i].replacement, type: ELEMENTS[i].type });
}
}
}
function replaceEls(html, elProperties) {
var pattern = elProperties.type === 'void' ? '<' + elProperties.tag + '\\b([^>]*)\\/?>' : '<' + elProperties.tag + '\\b([^>]*)>([\\s\\S]*?)<\\/' + elProperties.tag + '>',
regex = new RegExp(pattern, 'gi'),
markdown = '';
if(typeof elProperties.replacement === 'string') {
markdown = html.replace(regex, elProperties.replacement);
}
else {
markdown = html.replace(regex, function(str, p1, p2, p3) {
return elProperties.replacement.call(this, str, p1, p2, p3);
});
}
return markdown;
}
function attrRegExp(attr) {
return new RegExp(attr + '\\s*=\\s*["\']?([^"\']*)["\']?', 'i');
}
// Pre code blocks
string = string.replace(/<pre\b[^>]*>`([\s\S]*)`<\/pre>/gi, function(str, innerHTML) {
innerHTML = innerHTML.replace(/^\t+/g, ' '); // convert tabs to spaces (you know it makes sense)
innerHTML = innerHTML.replace(/\n/g, '\n ');
return '\n\n ' + innerHTML + '\n';
});
// Lists
// Escape numbers that could trigger an ol
// If there are more than three spaces before the code, it would be in a pre tag
// Make sure we are escaping the period not matching any character
string = string.replace(/^(\s{0,3}\d+)\. /g, '$1\\. ');
// Converts lists that have no child lists (of same type) first, then works it's way up
var noChildrenRegex = /<(ul|ol)\b[^>]*>(?:(?!<ul|<ol)[\s\S])*?<\/\1>/gi;
while(string.match(noChildrenRegex)) {
string = string.replace(noChildrenRegex, function(str) {
return replaceLists(str);
});
}
function replaceLists(html) {
html = html.replace(/<(ul|ol)\b[^>]*>([\s\S]*?)<\/\1>/gi, function(str, listType, innerHTML) {
var lis = innerHTML.split('</li>');
lis.splice(lis.length - 1, 1);
for(i = 0, len = lis.length; i < len; i++) {
if(lis[i]) {
var prefix = (listType === 'ol') ? (i + 1) + ". " : "* ";
lis[i] = lis[i].replace(/\s*<li[^>]*>([\s\S]*)/i, function(str, innerHTML) {
innerHTML = innerHTML.replace(/^\s+/, '');
innerHTML = innerHTML.replace(/\n\n/g, '\n\n ');
// indent nested lists
innerHTML = innerHTML.replace(/\n([ ]*)+(\*|\d+\.) /g, '\n$1 $2 ');
return prefix + innerHTML;
});
}
}
return lis.join('\n');
});
return '\n\n' + html.replace(/[ \t]+\n|\s+$/g, '');
}
// Blockquotes
var deepest = /<blockquote\b[^>]*>((?:(?!<blockquote)[\s\S])*?)<\/blockquote>/gi;
while(string.match(deepest)) {
string = string.replace(deepest, function(str) {
return replaceBlockquotes(str);
});
}
function replaceBlockquotes(html) {
html = html.replace(/<blockquote\b[^>]*>([\s\S]*?)<\/blockquote>/gi, function(str, inner) {
inner = inner.replace(/^\s+|\s+$/g, '');
inner = cleanUp(inner);
inner = inner.replace(/^/gm, '> ');
inner = inner.replace(/^(>([ \t]{2,}>)+)/gm, '> >');
return inner;
});
return html;
}
function cleanUp(string) {
string = string.replace(/^[\t\r\n]+|[\t\r\n]+$/g, ''); // trim leading/trailing whitespace
string = string.replace(/\n\s+\n/g, '\n\n');
string = string.replace(/\n{3,}/g, '\n\n'); // limit consecutive linebreaks to 2
return string;
}
return cleanUp(string);
};
if (typeof exports === 'object') {
exports.toMarkdown = toMarkdown;
}
Agent.receive = function() {
var events = this.incomingEvents();
for(var i = 0; i < events.length; i++) {
this.createEvent({ 'title': toMarkdown(events[i].payload.title), 'retweeted': toMarkdown(events[i].payload.retweeted) });
}
}
3. 推送消息到钉钉群
新建一个 huginn 的 Post Agent,配置如下:
{
"post_url": "{% credential ding_url %}",
"expected_receive_period_in_days": "1",
"content_type": "json",
"method": "post",
"payload": {
"msgtype": "markdown",
"markdown": "{\"title\":\"{{title | escape}}\",\"text\":\"#### {{title | escape}} \\n > {{retweeted | escape}} \"}"
},
"headers": {
},
"emit_events": "false",
"no_merge": "false",
"output_mode": "clean"
}
credential 里是我的钉钉群机器人的 url,这个 url 在添加群机器人后可以获得
这里需要注意的是每个字段都需要做 escape,如 {{title | escape}} 。效果也可以随意调整,钉钉的文档在 这里